.svg)


Unlocking Infrastructure for Real-Time Machine Learning with Bloom Filters
September 8, 2025
Integrating advanced data science models into production systems presents unique engineering challenges, particularly concerning deployment efficiency, scalability, and operational transparency. At Digital Turbine, our recent experience with machine learning model integration for DT Exchange highlighted a series of technical limitations within our existing infrastructure that impeded rapid iteration and optimal performance.
Digital Turbine’s DT Exchange is a sophisticated, mobile-first, real-time bidding (RTB) ad exchange that serves as a central hub for the automated buying and selling of mobile app ad inventory. At its core, the platform operates on a high-speed, low-latency auction engine that uses the OpenRTB protocol to facilitate instantaneous transactions between app publishers (supply) and advertisers (demand). This is supported by a robust SDK for seamless integration, and advanced machine-learning algorithms that provide critical functions such as yield optimization, user targeting, and fraud detection, ensuring a highly efficient and valuable marketplace for all participants in the mobile advertising ecosystem.
Scaling Challenges of Large Feature Exclude Lists
In order to optimize efficiency while controlling computational costs, our Data Science team develops predictive models that guide bidding decisions within the Exchange. These models determine which bidders are eligible to enter each auction and dynamically set the optimal bid price based on multiple contextual dimensions.
The predictive models generate large-scale exclude lists such as a list of bidders excluded for low profitability in a given auction context. The exclude lists are stored as Parquet files, where each entry represents an entity (e.g., a bidder) and is associated with a feature vector, for example: device operating system, device model, and connection type. Historically, these models used a relatively small set of features, enough to run efficiently, but limiting the modelʼs ability to capture richer behavioral and contextual patterns.
To unlock the full potential of these models, we aim to remove constraints on how many features can be included in each vector. This allows the inclusion of a broader set of features, improving prediction accuracy and decision quality.
However, more features not only enlarge each vector but also multiply the total number of vectors due to feature permutations. This growth creates serious memory and query performance challenges in our highly distributed Exchange system, which processes over 90 billion auction requests per day with peak traffic exceeding 1.5 million QPS, all while operating under real-time constraints with HTTP timeout typically between 250 ms and 1,000 ms.
Storing the entire exclude list as a HashSet in memory within each service instance is not feasible due to excessive memory requirements. Likewise, keeping these lists in a centralized cache is problematic, as every real-time lookup introduces network latency and potential bottlenecks. These constraints demand a more compact and efficient data representation that can be served at scale without sacrificing latency or throughput.
Solution
The Exchange service is a high-throughput server handling massive request volumes and as mentioned earlier most of our models are binary in terms of their output, thus a probabilistic data structure, in particular Bloom filter, is a great choice when a small amount of inaccuracy is acceptable in return of better performance and reduced memory usage instead of a traditional HashSet. A probabilistic data structure is a compact data structure that utilizes randomized algorithms to deliver results with bounded approximation error, making it useful for large datasets where memory efficiency is more important than perfect accuracy. Bloom filter is a probabilistic data structure used for membership testing. The Bloom filter may return false-positives but never false-negatives, it uses a bit array of size m and hash functions to test whether an element is in a set. The required size m of the filter depends on the expected number of elements n and the desired false-positive probability p, and can be approximated by the formula:
Analysis
This analysis assumes that the application runs on a Java Virtual Machine (JVM) and compares the memory efficiency of using a Bloom filter versus a traditional HashSet for storing exclude lists.
A modern, "rich" model includes 40–50 features, a significant increase compared to older models that were relatively sparse, with only 4–8 features. For a model with 50 features, the memory usage can be broken down as follows:
- 10 long fields: 10 × 8 bytes = 80 bytes
- 10 int fields: 10 × 4 bytes = 40 bytes
- 5 boolean fields: 5× ~1 bytes ≈ 5 bytes
- 25 String fields: 25 × ~35 bytes ≈ 875 bytes (assuming an average of 35 bytes per string, including the characters and JVM object metadata)
In addition to the basic data fields, each element has an object and HashMap entry overhead of approximately 40 bytes. This brings the total size of each entry to roughly 1,000 bytes, or 1 KB.
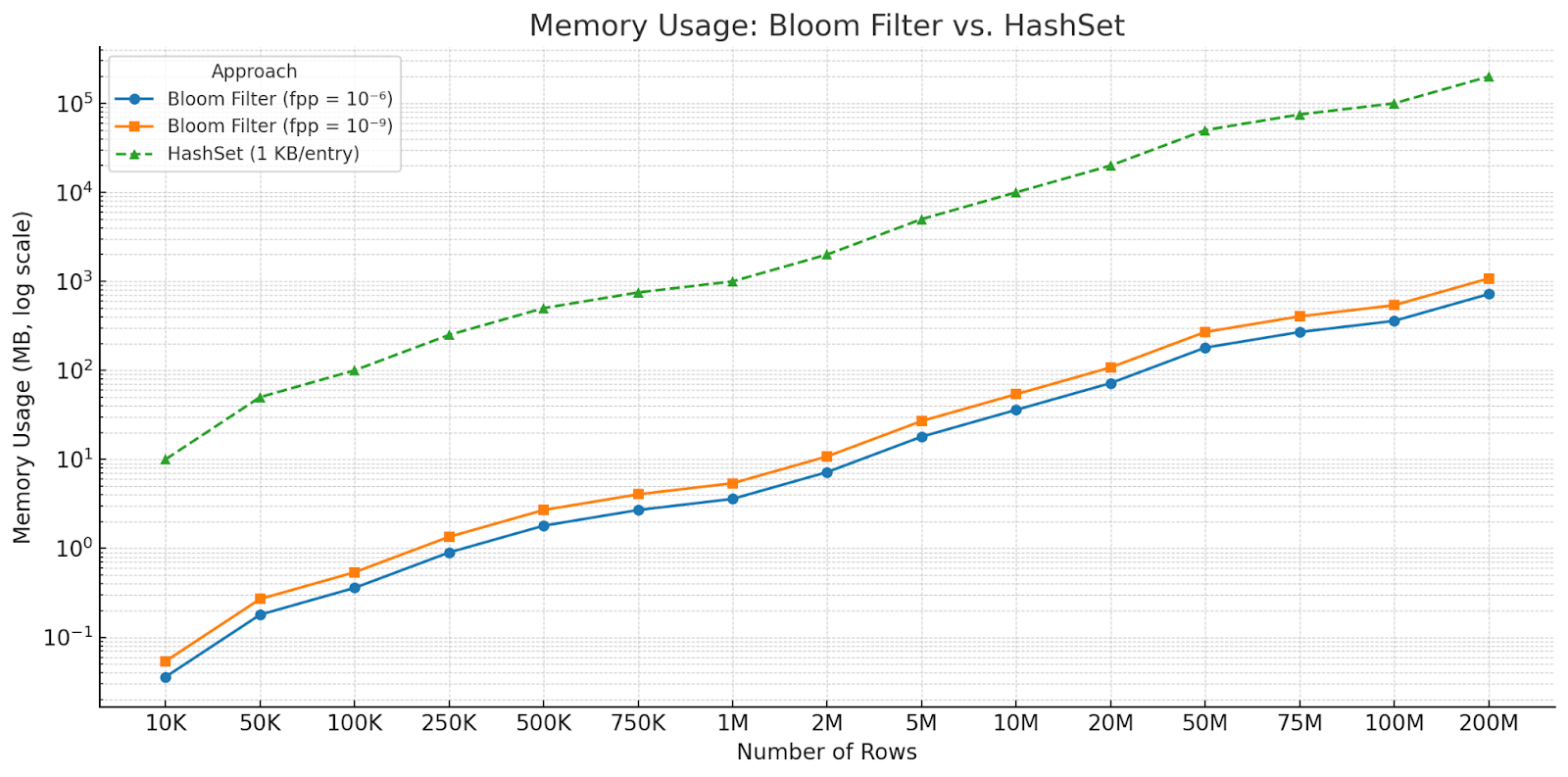
To better understand the trade-offs between different data structures for handling this problem, we can compare the memory usage of a HashSet with a Bloom filter. The table below illustrates the difference in memory consumption between the two approaches, showing how a Bloom Filter can achieve significant memory savings at the cost of a small, configurable false-positive rate.
A broader understanding of the trade-offs between these approaches is best visualized. The following graph, which uses a logarithmic scale, provides a more comprehensive comparison.
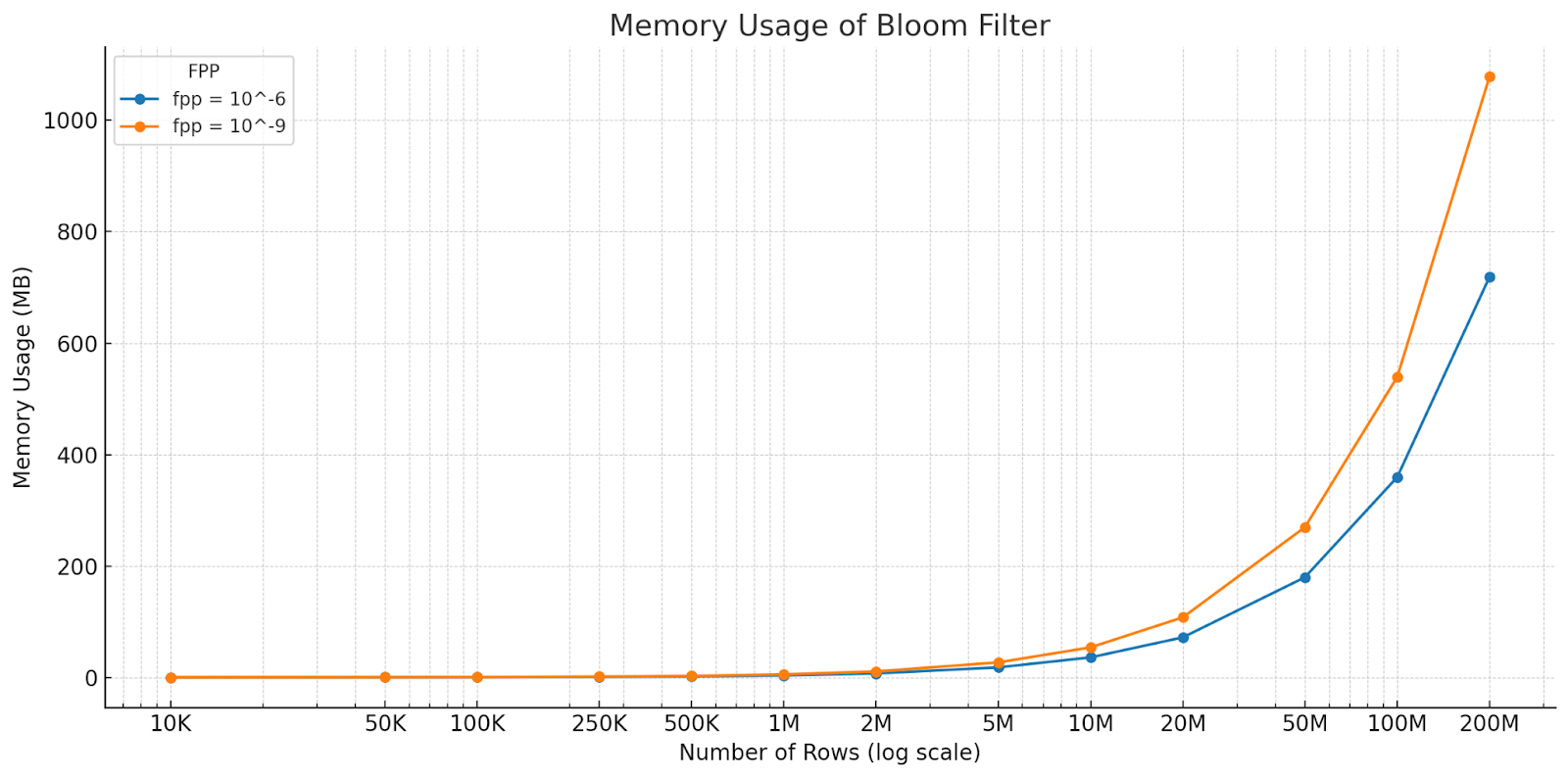
The next graph illustrates the relationship between the false-positive probability and the size of the Bloom filter in bytes. As discussed earlier, this clearly demonstrates the inherent trade-off in this data structure between accuracy and space efficiency.
Solution Implementation
Overview
The Bloom filter transformation pipeline is implemented as a Kubernetes CronJob ETL service written in Scala, leveraging the Akka Actor framework for concurrent and efficient processing. The pipeline is responsible for detecting new Parquet files in a Google Cloud Storage (GCS) bucket, transforming them into Bloom filters, using the Guava library, and uploading the results back to GCS. Bloom filters are generated on an hourly basis, ensuring that models stay fresh and reflect the most recent data. Later, the Exchange service will periodically download these Bloom filter files to enable fast in-memory lookups during real-time processing of auctions and bids.

Why Use ETL?
Offloading Bloom filter generation to a dedicated ETL pipeline is a strategic design decision that should improve the Exchange service performance. The Exchange service is optimized for high-throughput and real-time load, and should remain lightweight and focused on serving traffic. Generating Bloom filters from Parquet files involves heavier processing tasks including file reading, key extraction, and hashing, which can introduce latency and memory pressure if handled at auctionsʼ handling time. Thus, by offloading this workload to an ETL process, we reduce the Exchange computational overhead and keep resource usage stable.
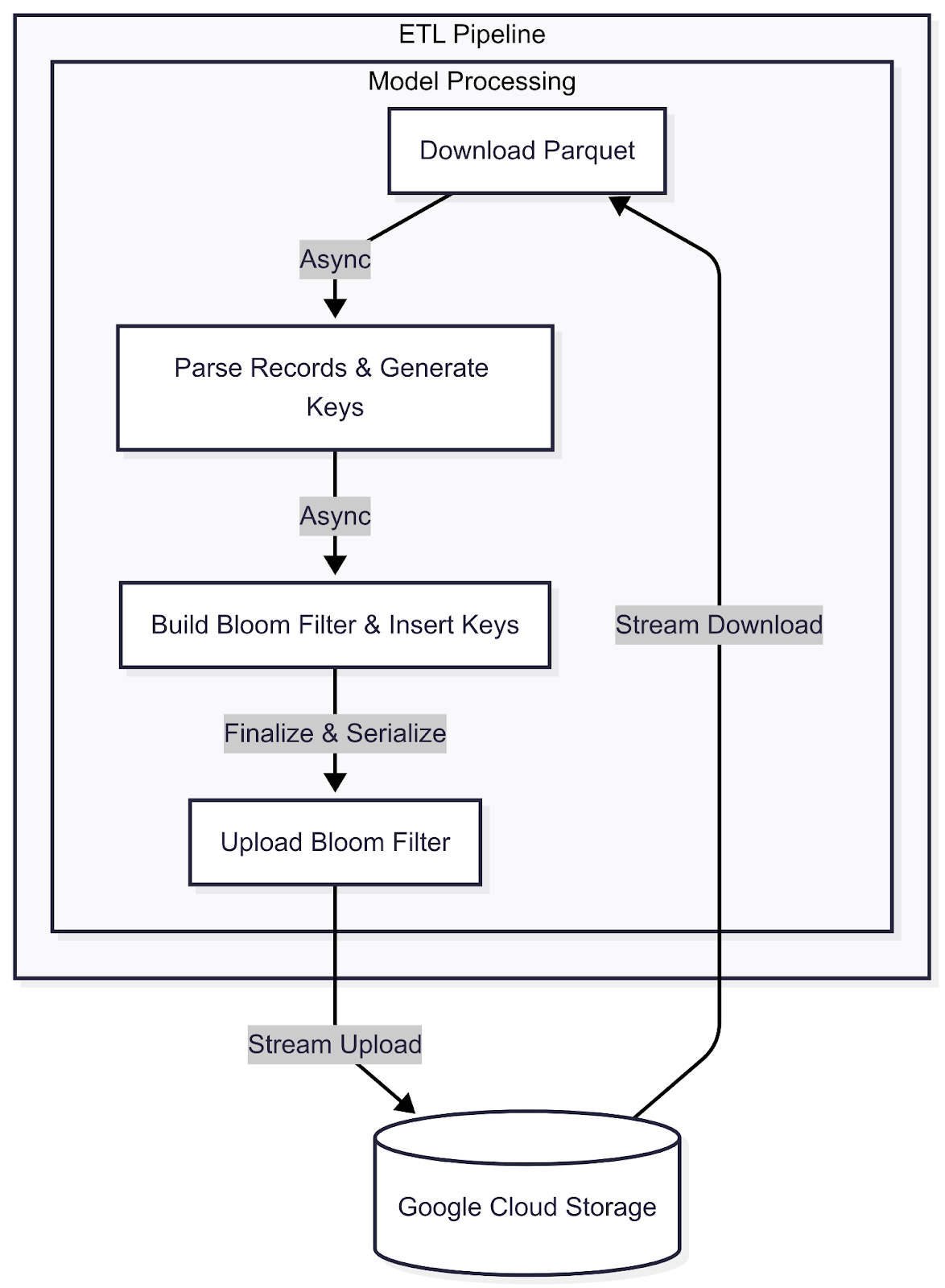
Architecture Design
The Manager Actor orchestrates the entire processing lifecycle for multiple model files within a single CronJob pod. It dynamically manages the other actors assigned to each model.
For each model, the Manager dynamically creates two sub-actors:
- Parquet Reader Actor: This actor is responsible for downloading a Parquet file from GCS and streaming its records.
- Bloom Filter Builder Actor: This actor receives the streamed records and builds a Bloom filter in memory before uploading the final filter back to GCS.
Communication between the Parquet Reader and the Bloom Filter Builder is fully asynchronous to prevent any blocking behavior.
This design offers several key advantages:
- Streaming processing: It avoids loading an entire file into memory at once.
- Multi-threaded execution: Each actor runs independently, which allows for concurrent processing of each model.
- Minimal disk I/O: All operations are performed in memory, eliminating the need to write intermediate data to disk.
Scalability
To ensure scalability, the overall pipeline allows deployment across multiple pods, each processing a subset of models. This horizontal distribution guarantees that model files are processed in parallel across multiple machines. Each pod independently manages its assigned models without interference and collisions, leading to efficient and controlled resource utilization.
Key Generation
Each Parquet record is converted into a key by concatenating the values of selected columns, in a predefined and consistent order. Since the Bloom filter checks for membership based on the raw byte hash of a given key, any change in the keyʼs construction might produce a completely different hash. This means that if the key is built one way during the ETL job and a different way when it is later queried, the lookup will fail. For instance, if the ETL generates a key as 12345|US (combining a device ID with its country code), but the Exchange service reconstructs it as US|12345, the two strings will hash differently. As a result, the entry might never be found, even though both hashes contain the same information. To ensure reliable results, both components must share a strict serialization contract, keeping the Bloom filter creation and querying in perfect sync, even when the schema changes whether by adding, removing, or modifying features.
Conclusion
By introducing the Bloom filter-based approach, weʼve transformed the way our Exchange service handles predictive models in a high-throughput, memory-constrained environment. This solution delivers dramatic memory savings compared to traditional HashSets, while maintaining real-time lookup performance with negligible false-positives.
The compact nature of Bloom filters unlocks the ability for our Data Science team to enrich our models with more features and data without being limited by infrastructure memory constraints. In addition, offloading the transformation process to a dedicated ETL pipeline further isolates heavy computations, keeping the Exchange service lean and optimized for high-throughput serving performance.
Ultimately, this architecture removes infrastructure bottlenecks and dependencies between engineering and data science teams, enabling scalable deployment of complex models, and improved bidding decisions, all while maintaining the speed and reliability required for large-scale, real-time, ad tech systems.
.jpg)

.webp)
.jpg)


