.svg)
.webp)

Currently, Google BigQuery is a distinctive data warehouse platform capable of efficiently managing large volumes of data. In most cases, complex administrative tasks or installation processes aren't necessary. But is it so easy? GBQ can autoscale and process petabytes of data, providing a fast response to your query as long as you can afford unlimited slots. But what if you want to control your costs and limit the number of slots used in your projects? At that point, you need to configure your BigQuery reservations properly. This article will describe our journey through optimizing BigQuery reservations and BigQuery costs in general.
BigQuery slots, what is that?
Google says that a BigQuery slot is a virtual CPU used to execute SQL queries. But what does it mean in real life? If you open the BigQuery Monitoring tab, you will not see a sort by CPU or RAM load, and you can't choose the processor type or number of cores in the GBQ configuration. It means you can't control computing resources at all.
The main idea of BigQury is a hardware separation of the compute and storage layers. This distributed architecture provides speedy execution of SQL requests as long as you minimize writing to disk.
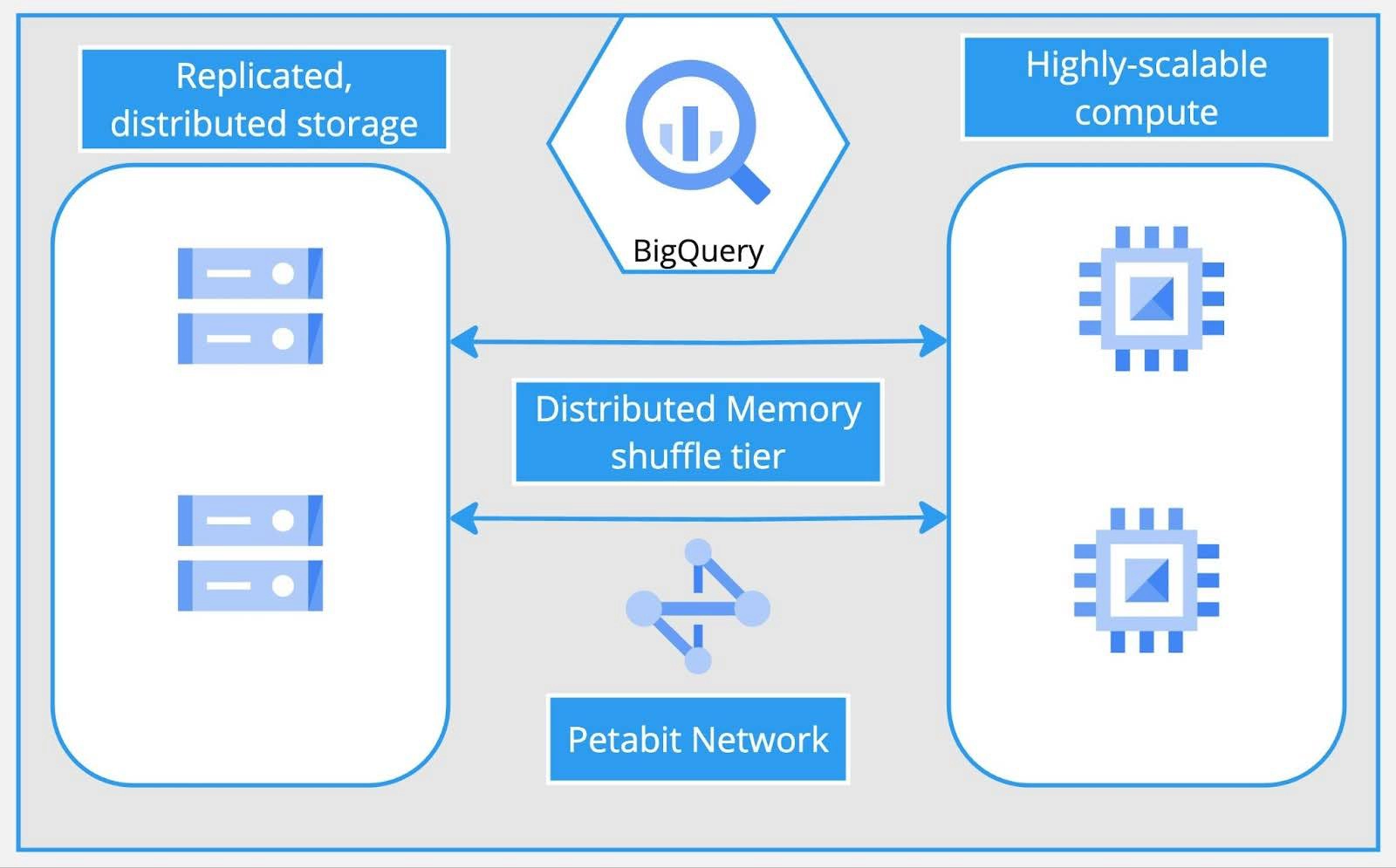
So let's suggest that slots are ephemeral processing units of time needed for your query to provide results. And in practice, you need to care about the optimization of your jobs as you will be billed for each of these steps:
- Elapsed time
- Slot time consumed
- Bytes shuffled
- Bytes spilled to disk, etc.
Here is an example of our BI reports job execution to imagine how complex it could be.
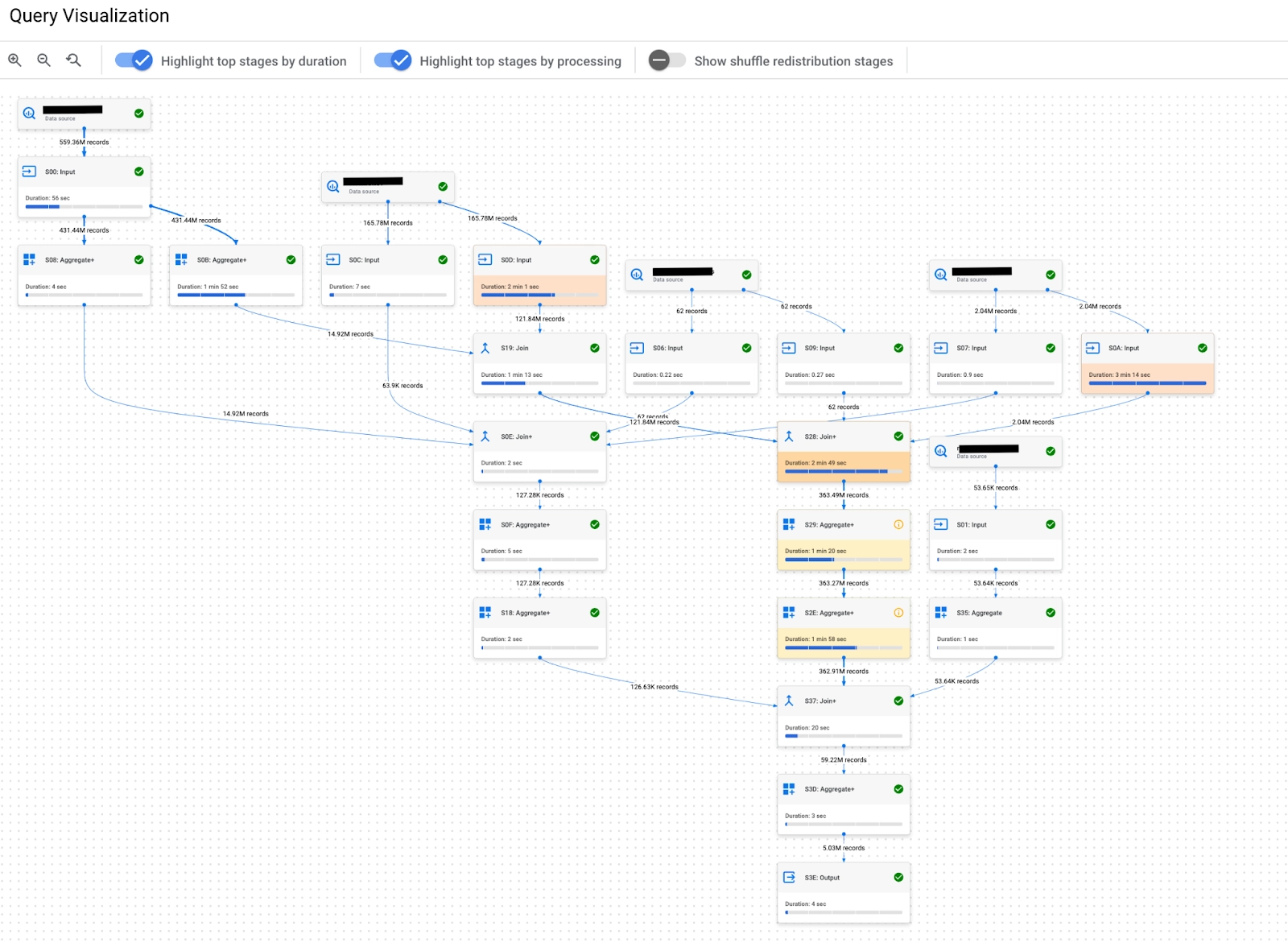
BigQuery reservation types
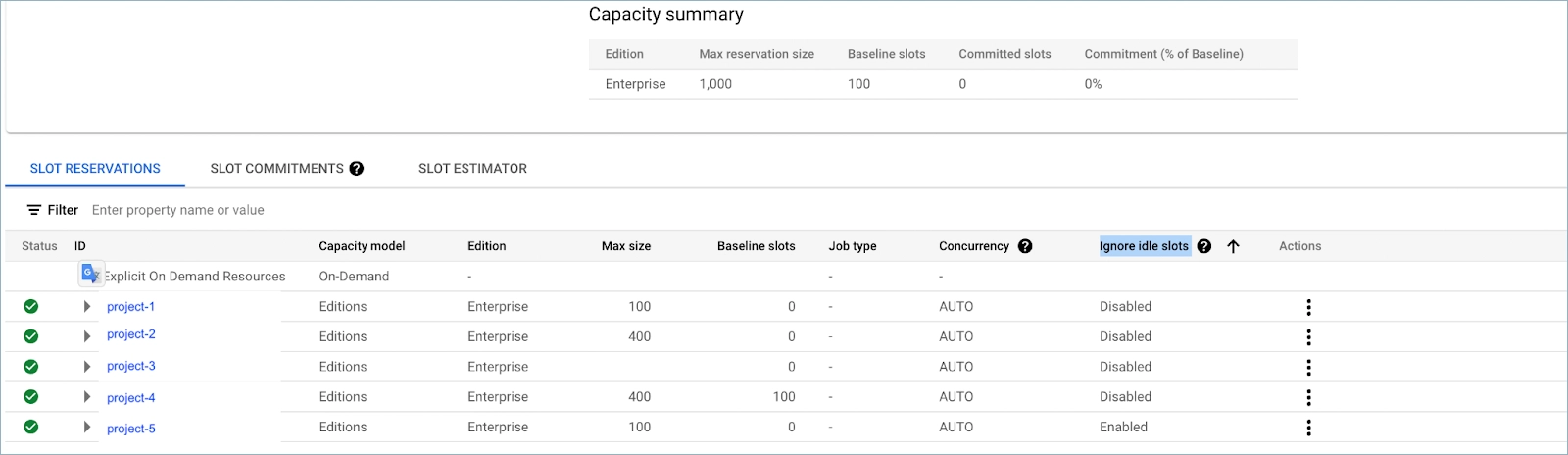
To control the number of your slots per project BigQuery has a Capacity Management service in which you can configure Reservations. There are three editions of BigQuery reservations available for users: Standard, Enterprise, and Enterprise Plus. Here is a cost and feature comparison table for all three reservation types:
The biggest advantage of Enterprise reservation is Materialized view (MV) support and autoscaling with baseline slots. Baseline slots provide gradual control on whether reservations need to scale up.
In our case, one of the projects utilized more than 90% of the slots and did not use MV features except for querying existing ones. So the decision was to use Standard reservation as all queries were running against existing MV in another project.
To access MV data from other projects we have configured Analytics Hub service. In short, Analytics Hub is a data exchange platform that enables the configuration of distributed dataset access sharing. For our particular case, we have used Pub/Sub private subscription functionality with the main data exchange created in our Production project.
The biggest downside to not using the same type of reservation is that you can't share free slots among other projects. But in our case, we were able to lower the cost by isolating the "noisy neighbor" and choosing a much cheaper Standard billing model.
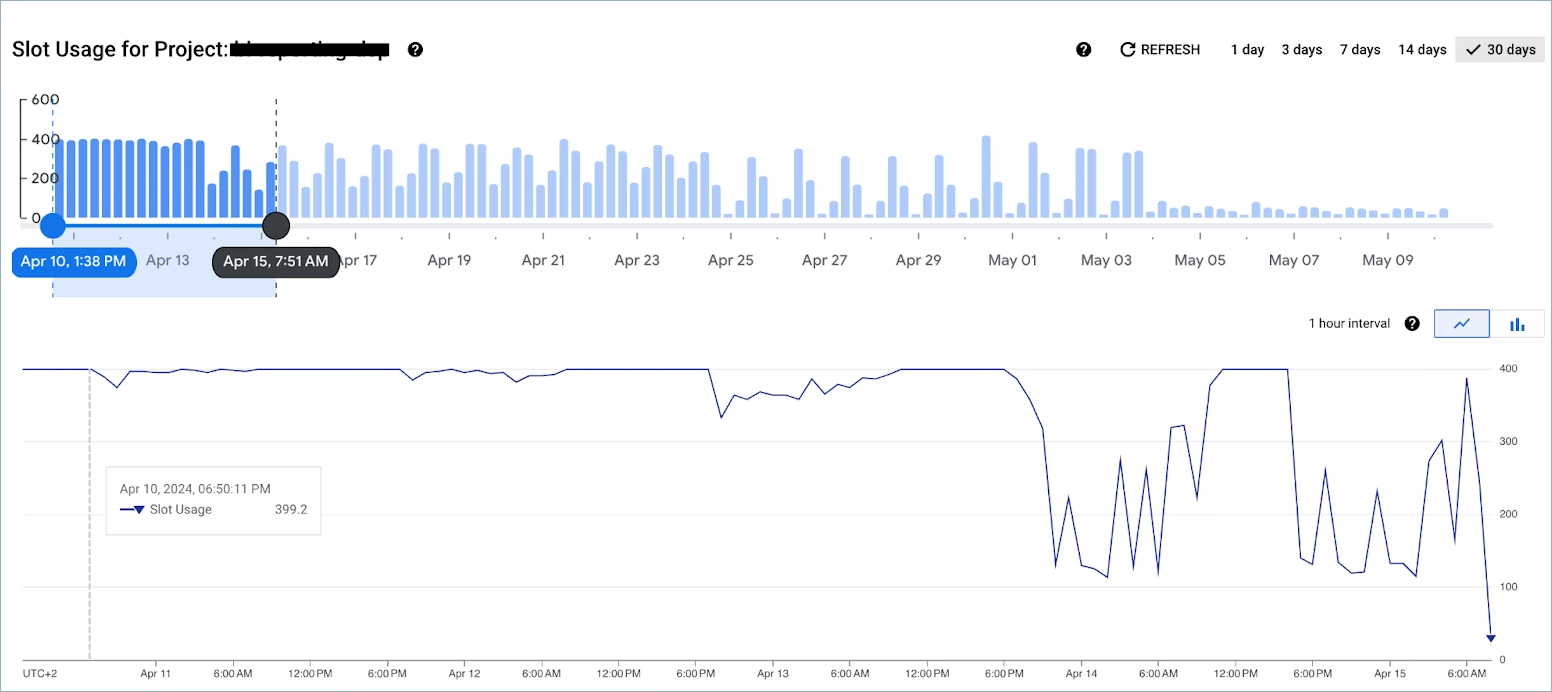
After some time, the query was optimized and we changed the reservation back to Enterprise by putting Baseline slots to 0 and enabling the Ignore idle slots option.
Ignore idle slots is disabled by default and it does not prevent taking more slots from other reservations if they are available. For Standard reservations, Ignore idle slots is always enabled and can not be turned off. Simply put, Ignore idle slots should be enabled only when you want to prevent some projects from utilizing shared slots. So in the end we switched fully to Enterprise reservation and here is our final slots configuration.
As you can see all our jobs now use slots non-linearly, and we can utilize autoscaling and slots sharing among all projects.
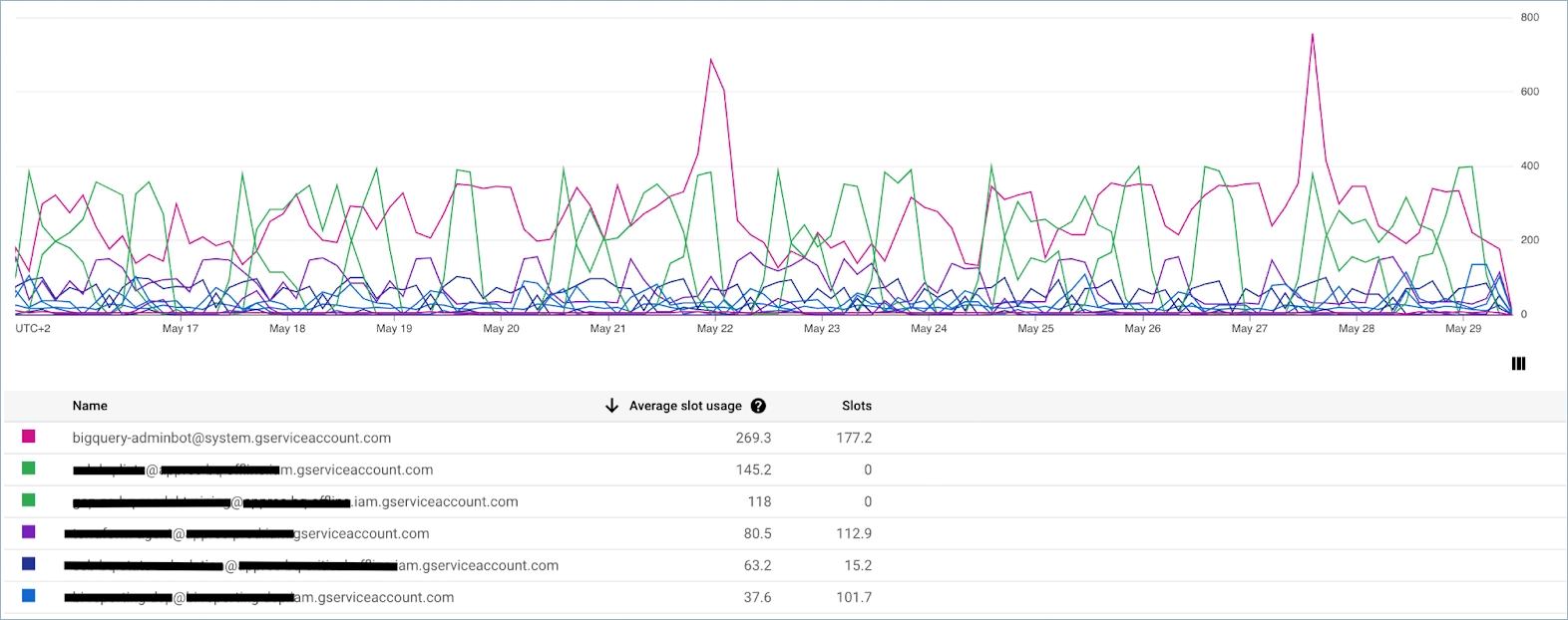
One of the projects has Baseline slots set to 100 as the average load is always more than 150 slots, and we don't want to trigger autoscale when the load increments by 100.
The decision-making for choosing the Edition based on reservations needs is as follows:
.webp)
Segregation of users for BigQuery reservations
As mentioned previously, you can use Analytics Hub to share access to different tables, but it is also important to identify billing costs for each BigQuery request.
To separate BigQuery requests, we have created service accounts in each project. This functionality helps us determine which user is requesting more slots and needs to be moved to another reservation.
Also, the sharing access model helps us to secure production data as it provides just Read/View access threw Analytics Hub.
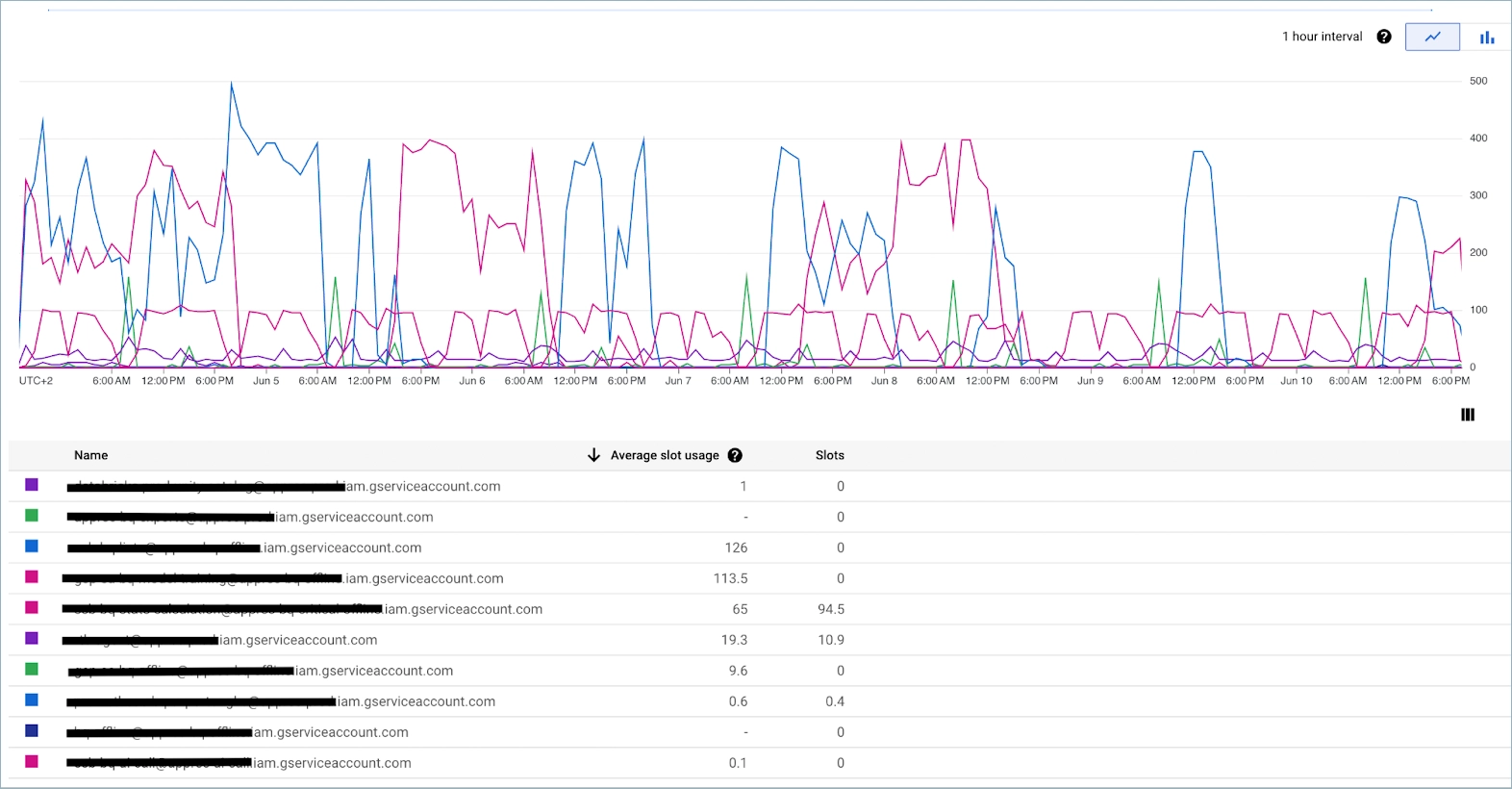
Materialized Views Updates
It is important to say that even switching to separate reservations and projects will not help with totally isolating billing for slots. The reason is that in BigQuery, updating of Materialized Views is processed in the project where the dataset is located, so perhaps it is your main production project. Moreover, these updates are run by Google internal users which you can't control.
By default, materialized views are automatically refreshed within 5 minutes of a change to the base tables, but not more frequently than every 30 minutes.
How can you address this? There are several workarounds:
- Increase default auto-refresh timeout. In our case, it is 1 hour.
- Disable MV auto-refresh and create a scheduled query which you will run before generating reports.
- Move MV to the sample project where your target reservation is.
- Do not use MV.
Here is an example of slot usage caused by BigQuery internal user for MV update:
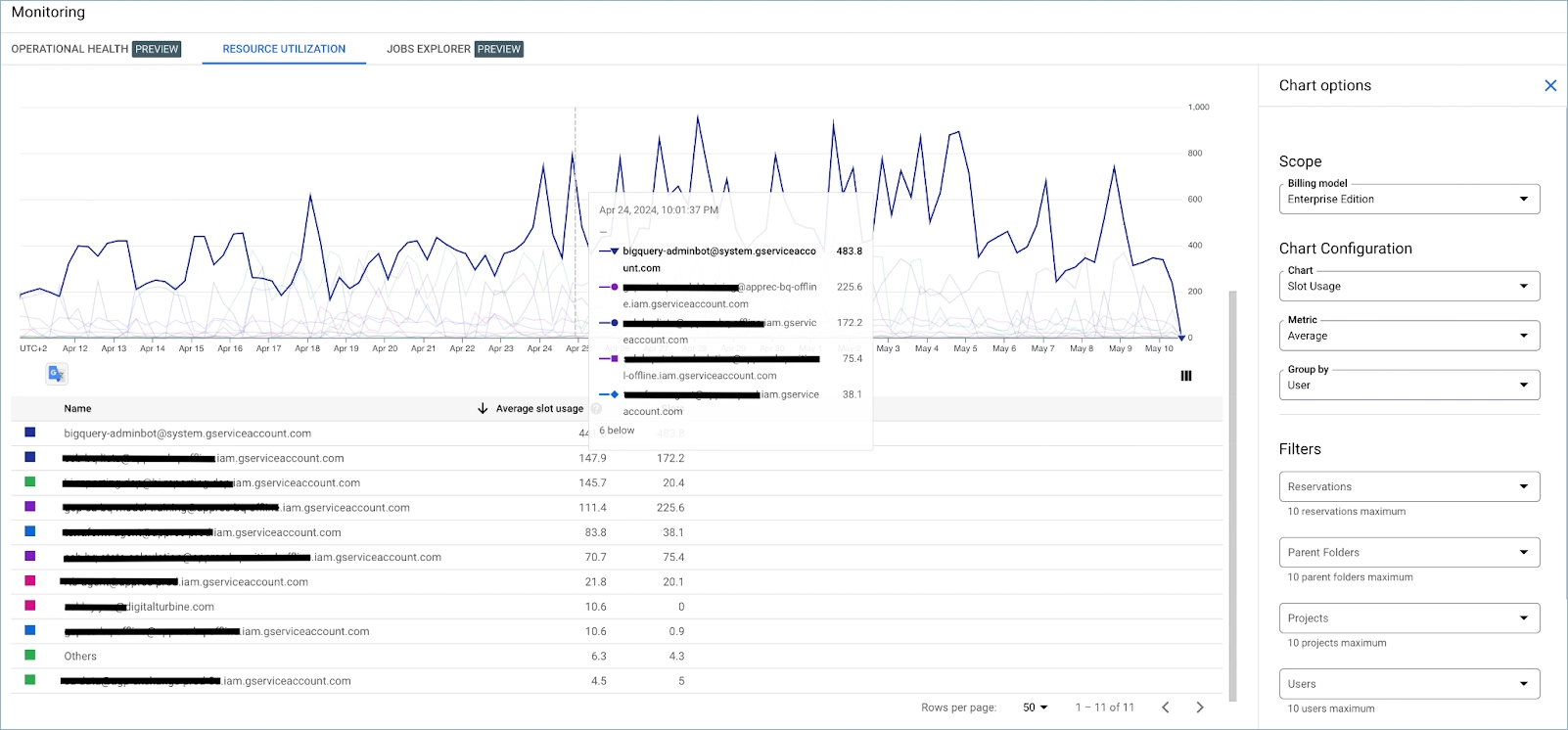
Who is using the slots?
You can always check BigQuery internal Monitoring to analyze the data.
But if you prefer to get more data, you can run an SQL query against INFORMATION_SCHEMA metadata.
SELECT
user_email,
project_id,
creation_time,
query,
job_id,
total_slot_ms
from `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP("2024-04-30") AND TIMESTAMP("2024-05-02")
order by total_slot_ms desc
LIMIT 10Also, you can retrieve SQL queries from a particular job for further analysis by your Data Engineers.
SELECT
creation_time,
query,
user_email,
total_slot_ms,
total_bytes_processed,
total_bytes_billed
FROM `name_of_your_project.region-us.INFORMATION_SCHEMA.JOBS`
WHERE creation_time BETWEEN TIMESTAMP("2024-04-22") AND TIMESTAMP("2024-04-24")
AND job_id = 'materialized_view_refresh_SomeRaNdOMsmthting'One of the latest updates for BigQuery internal Monitoring is the Job Explorer panel. It is a handy tool because you can sort by a particular user and then explore the query itself.
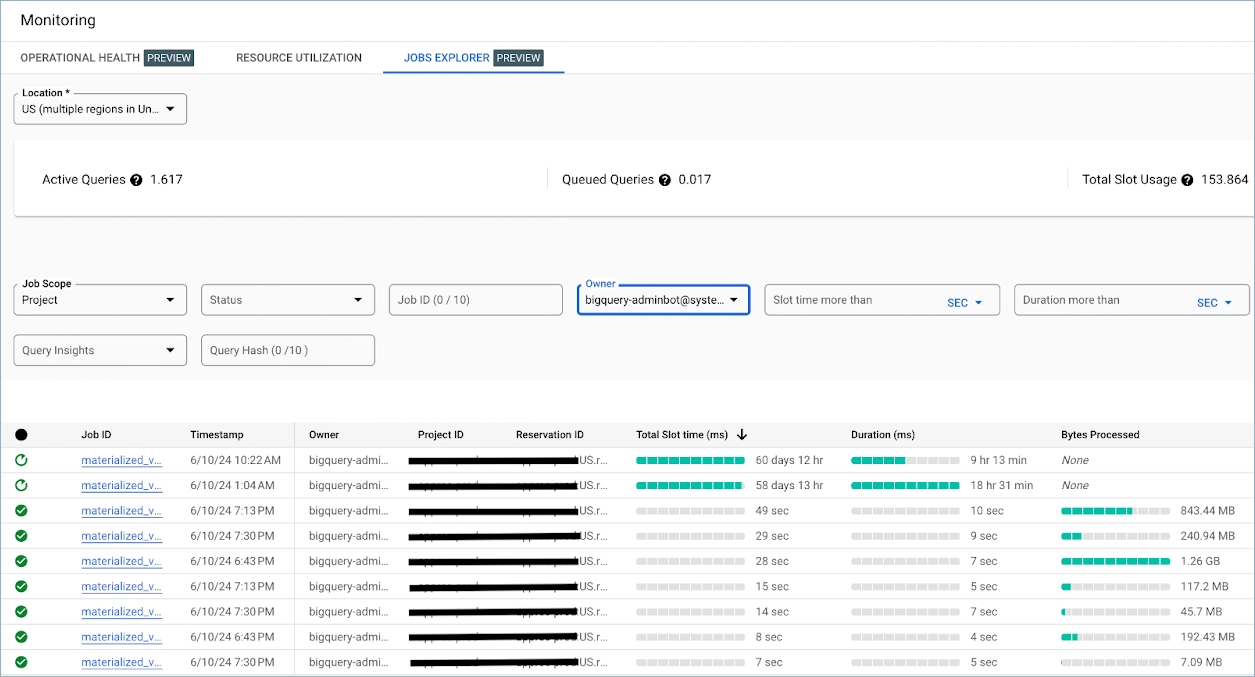
BigQuery reservation as a Code
In the cloud world, you should always have a Data Recovery plan and avoid manual configuration.
With DevOps philosophy in mind, we created the Terraform module for reservation management as Google does not provide one.
In a nutshell, this is a module that combines two Terraform resources: "google_bigquery_reservation" + "google_bigquery_reservation_assignment"
This approach allows us to consolidate all configurations into a single Terragrunt file.
nputs = {
region = "us-central1"
reservations = {
someproject-prod = {
name = "someproject-prod"
project = "someproject-prod"
bq_region = "us"
slot_capacity = 0
ignore_idle_slots = false
edition = "ENTERPRISE"
concurrency = 0
max_slots = 200
},
someproject-bq-critical = {
name = "someproject-bq-critical"
project = "someproject-prod"
bq_region = "us"
slot_capacity = 200
ignore_idle_slots = false
edition = "ENTERPRISE"
concurrency = 0
max_slots = 500
},
bi-reports = {
name = "bi-reports-ent"
project = "someproject-prod"
bq_region = "us"
slot_capacity = 0
ignore_idle_slots = true
edition = "ENTERPRISE"
concurrency = 0
max_slots = 100
},
bi-reports = {
name = "bi-reports"
project = "someproject-prod"
bq_region = "us"
slot_capacity = 0
ignore_idle_slots = false
edition = "ENTERPRISE"
concurrency = 0
max_slots = 200
}
}
assignments = {
assignment-someproject-prod = {
assignee = "projects/someproject-prod"
job_type = "QUERY"
reservation_name = "someproject-prod"
},
assignment-someproject-bq-critical = {
assignee = "projects/someproject-bq-critical"
job_type = "QUERY"
reservation_name = "someproject-bq-critical"
},
assignment-someproject-ui-call = {
assignee = "projects/someproject-ui-call"
job_type = "QUERY"
reservation_name = "someproject-bq-critical"
},
assignment-bi-reports = {
assignee = "projects/bi-reports"
job_type = "QUERY"
reservation_name = "bi-reports"
},
assignment-someproject-bi-reports = {
assignee = "projects/someproject-bi-reports"
job_type = "QUERY"
reservation_name = "bi-reports"
}
}
}Conclusion
Managing BigQuery reservations is not an easy task. You should always analyze and monitor query fluctuations to choose the best editions. Remember, if you mix reservation types, you can't share slots among projects with different billing plans.
From our experience, we were able to reduce the number of slots used by 30%.
Due to the combination of Standard and Enterprise reservations, we were able to support concurrent loads from all our projects, keeping the BigQuery budget at an acceptable level.
By the end of our journey, we had brought our global BigQuery costs down to just 20% of what they once were. While query code optimization also played a significant role, the majority of the savings came from the earlier steps we took—though that’s a story for another article!


.webp)
.jpg)


