.svg)


Digital Turbine has developed a monetization platform for game developers. As such, we have a massive amount of data and customers who require the ability to analyse metrics across arbitrary dimensions.
Customers want to see data across many dimensions and therefore, we need a very efficient time-series database that allows us to manage this amount of data. Scalability, reliability and efficiency are fundamental for our use case. Druid is a highly scalable, reliable and efficient column-oriented database which is the heart of the reporting pipeline at Digital Turbine.
Druid is broken down into many components, most of which you can scale independently or you can simply run everything on one server for a test or development environment. You can run it even in containers, if you want to.
For a production environment we run every component on a distinct server. This allows us to scale exactly where we have the bottleneck, but also provides high availability for every specific component.
Such solutions are not cheap and druid is no exception. But if you take advantage of Druid’s multicomponent and flexibility of cloud infrastructure you can make it much cheaper.
In this article I want to share our experience of running historical and ingestion components of Druid on Spot instances which allowed us to save two thirds of the cost and not to be afraid to lose data or suffer any major outages.
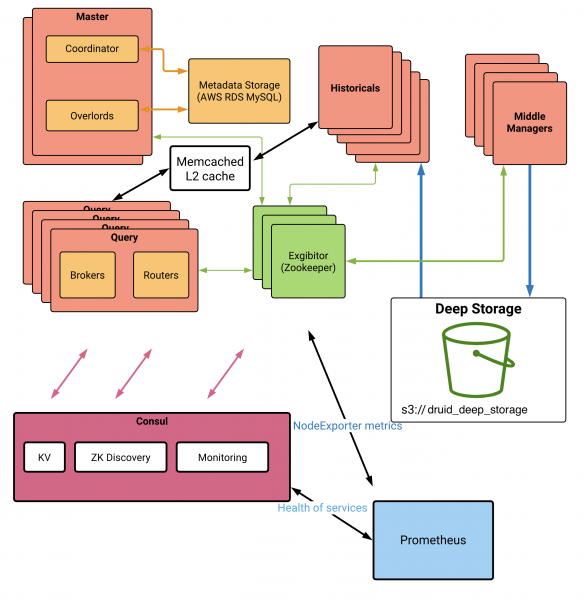
While we are not going to discuss here our entire Druid setup, it’s worth to mention the main components and their role:
- Master nodes are Druid “brain” and each contains two processes:
- Coordinator – tells data nodes how to manage data, distributes it, loads or drops it, checks data segments availability etc.
- Overlord – is a service that receives different types of tasks such as ingestion tasks, coordination tasks, compaction tasks, cleaning/killing tasks etc. and assigns them to workers
- Historicals nodes – responsible for storing data segments and processing queries for data it is responsible for.
- MiddleManagers nodes – these are ingesting nodes that process raw data and convert it into Druid format, upload to deep storage, update metadata. It can also ingest in real-time and then process queries for real-time data. Usually Middle Managers are settled on the same server as Historicals. However, at Digital Turbine we moved them out to separate servers to be more flexible in choosing instance types and perform autoscaling. To execute tasks, Middle Manager creates a special process, called peon, that runs in a separate JVM and forwards tasks to it. One Middle Manager could create multiple peons and one peon can execute one task at a time. The maximum number of peons per Middle Manager is configurable and depends on the amount of resources available on a Middle Manager server.
- Query nodes – receiving queries from clients and processing partial results from historical nodes
- Deep storage – this is a very important feature of Druid allowing us to use external shared storage (HDFS, AWS S3, EFS etc.) for storing cold data for backup and for transferring data between servers. So whenever Historicals need to download data it uses deep storage. All historical data can be deleted from historical servers and servers repopulate all data from deep storage. This also works if servers are terminated and new servers are spawn.
- Metastore – is an external relational database that contains metadata about data managed by a Druid. When new data is ingested (technically this is called a segment), overlord updates records so that other components are aware of new segments and can update their state (eventually leading to a download of a segment from the deep storage).
- ZooKeeper – most of the time components in Druid never talk directly to each other. Instead, all communication happens through a ZooKeeper. It is used to assign tasks to Historicals and Middle Managers from Overlord and Coordinator.
- Consul – is not a mandatory component of Druid, but we use it to avoid hardcoding of zookeeper nodes addresses (zk discovery on the diagram) on Druid servers and instead discover them with consul and render config with consul-template. Also we use consul health check together with consul prometheus exporter to monitor health of Druid services. Consul KV on the diagram is a key value store which we use to store Druid services parameters (like heap size for example, or direct memory size) which we often change while tuning Druid according to changes in load profile.
AWS Spot Instances
Spot instances are unused AWS compute resources that you can use with a discount of up to 90% of the On-Demand instances price. Their disadvantage is that AWS can reclaim Spot instances back when they are required. If the demand on Spot market is high, this could happen quite often. For this reason, you should usually run stateless services with immutable deployment on Spot instances.
Spot.io elastigroup
Spot.io (former Spotinst) is a company that offers advanced autoscaling groups (called elastigroups) with proprietary algorithms that allow in a predicted and cost-effective way to manage Spot instances, fallback to on-demand in case AWS doesn’t have available Spot instances, switch between different types of instances with focus on costs, provide insightful visual analytics and very responsive support.
One outstanding feature offered by spot.io is stateful elastigroup with Spot instances. It is not mandatory to use spot.io to have this feature, but it is not straightforward to reimplement.
If your service is built in a fault tolerant manner by leveraging elastigroup persistent mode, you can run stateful workload on Spot instances. The idea is simple, when the Spot instance is replaced, the new instance gets reattached EBS volumes of the old instance.
On-Demand and Spot AWS EC2 instances for Druid services
In the table below distribution of druid services between AWS EC2 On-Demand and Spot instances in our setup is illustrated. Green cells are services that we managed to put on spot instances and red are services that we run on on-demand instances.
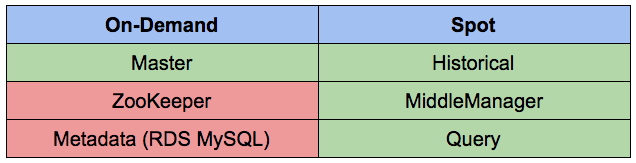
To run services on Spot instances we need to configure them to be fault tolerant. Let’s review every service specifically and possible tradeoffs to be considered before taking a decision on choosing either Spot or On-Demand EC2 instance:
Master nodes
If this service is down, Druid will continue serving queries but Historicals don’t receive new tasks for managing segments (download, rebalancing, drop). Middle Managers, in turn, stop ingesting new data. After master server is replaced automatically by autoscaling group, it continues creating new tasks for managing data and ingestion. It is also possible to have multiple master nodes, but then you must detect which is the leader and submit ingestion tasks there. This component doesn’t require many resources – m5.xlarge works well for our workload, so we decided that efforts to run it on Spot instances are not worth it and we use On-Demand in elastigroup with health checks and autohealing.
Query nodes
We run multiple query nodes behind AWS Load Balancer allowing us to distribute load and send requests on healthy servers only. If you run a query service on a Spot instance and it is reclaimed while processing, the query request fails and you must retry. This is the tradeoff we accepted and run Druid query service on multiple Spot EC2 instances.
ZooKeeper
Support fault tolerant setup by using multiple servers in zookeeper cluster. For example 3 nodes cluster tolerate one node could be lost. Since zookeeper is very crucial for Druid cluster work and there is no guarantee that only specific numbers of servers will be reclaimed be AWS at a time, we recommend to run at least a 3 nodes zookeeper cluster on On-Demand EC2 instances.
Metadata (PostgreSQL or MySQL)
We use AWS RDS which provides enough reliability but doesn’t have an option to use Spot instances. Metadata storage is crucial for all components of Druid cluster.
The most pricy things in our Druid are Historical and Middle Manager servers, so we will focus mostly on them in this article.
Middle Manager on Spot Instances
Let’s start with ingestion service, i.e. Middle Managers. We need Middle Manager servers only for executing tasks (ingestion, kill, compaction). When the Middle Manager is idle, it could be safely removed from the Druid cluster. If Middle Manager is reclaimed while executing a task, the Druid will retry this task on another available node.
For running druid in elastigroups we created AWS AMI images which contains:
- Druid
- Prepared and disabled systemd units for every druid service
- Consul client and configuration with health checks for Druid services
- Consul-template for generating druid configuration files with discovered addresses of zookeeper servers, and values for Druid parameters from consul key-value store
- Prometheus node exporter
Elastigroups for every Druid service are configured with userdata which enables specific Druid systemd service, i.e. master, query, middle manager or historical.
To prepare this AWS AMI we use Packer and Chef configuration management.
If you decide to use Chef configuration management, you can take a look at this cookbook as a starting point. Chef could be used with a central server to propagate changes on running servers or as serverless by using chef solo. Our choice is to use chef solo with policyfiles to deliver druid inside AWS AMI images.
Last step is to deploy elastigroup. We use the spot.io provider for terraform elastigroup. Also you can use spot.io UI and deploy it manually.
Save more on ingestion with autoscaling
Our ingestion workload is not static. We have a period batch of ingestions, some every few hours during the day, others once per day in the beginning of a new day. Autoscaling is a good procedure that allows you to save costs in this kind of scenario.
Druid has an embedded autoscaler, based on a number of pending tasks which supports AWS EC2, but it doesn’t work with Spot EC2 instances.
AWS ASG and spot.io elastigroup support autoscaling based on default (CPU usage for an instance) or custom metrics (using AWS CloudWatch) but it’s neither straightforward nor effective, also it’s not possible to downscale in a graceful and safe way by removing only idle Middle Manager servers.
To achieve this goal we decided to build our own autoscaling logic on top of spot.io and Druid APIs.
Tasks in Druid is a way Overlord assigns different types of work to middle manager servers. Tasks have different statuses – running, complete, waiting, and pending. To do autoscaling we use number of pending tasks.
Pending tasks are tasks that are waiting in the queue when some Middle Manager picks them up to execute. Every Middle Manager, as we discussed above, has configured capacity of peons. For example, by setting druid.worker.capacity = 4, one Middle Manager server will be able to execute 4 simultaneous tasks.
Druid API which could be used for autoscaling:
- Get number of current pending tasks:
Here we have 7 pending tasks. If one Middle Manager server has configured maximum 4 peons, we need to spawn 2 instances.
To do scale down in a safe and graceful way you should get the list of idle Middle Manager servers and then remove the required amount of servers from this list.
- Get idle Middle Managers you can use this Druid API:
To be on the safe side, we also want to disable middle managers, so we decided to remove before doing scale down by using this API.
- Disable Middle Manager:
For managing spot.io elastigroup we use python sdk.
At Digital Turbine we have created a python script and run it periodically by using airflow (of course lambda could be used here, however airflow is our default scheduled job infrastructure).
20 instances of ingest nodes provisioned by spot.io cost us around $100 per day. With autoscaling we pay around $30 per day and in addition we are sure that the druid is ready to cover the spikes of ingestion workload if needed without adjusting manually the number of provisioned instances.
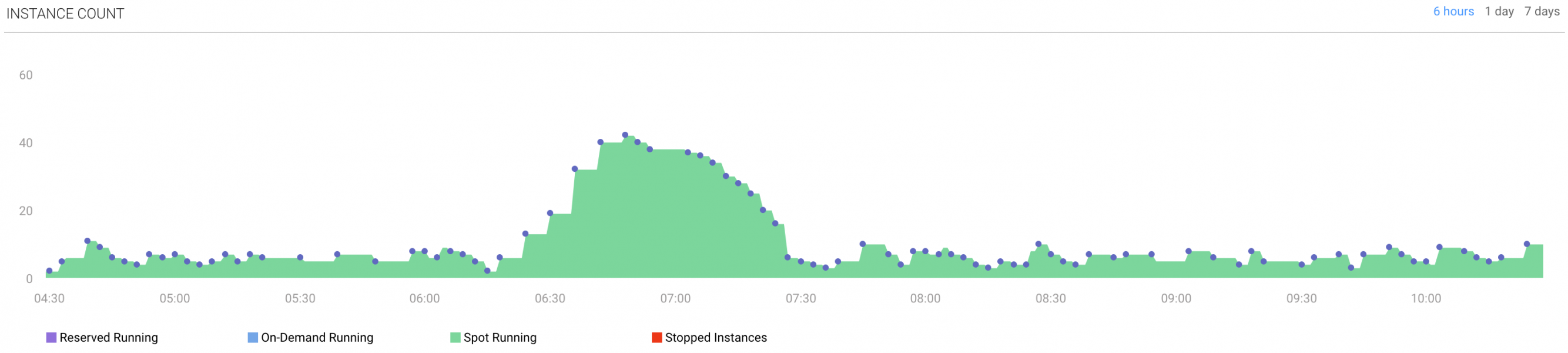
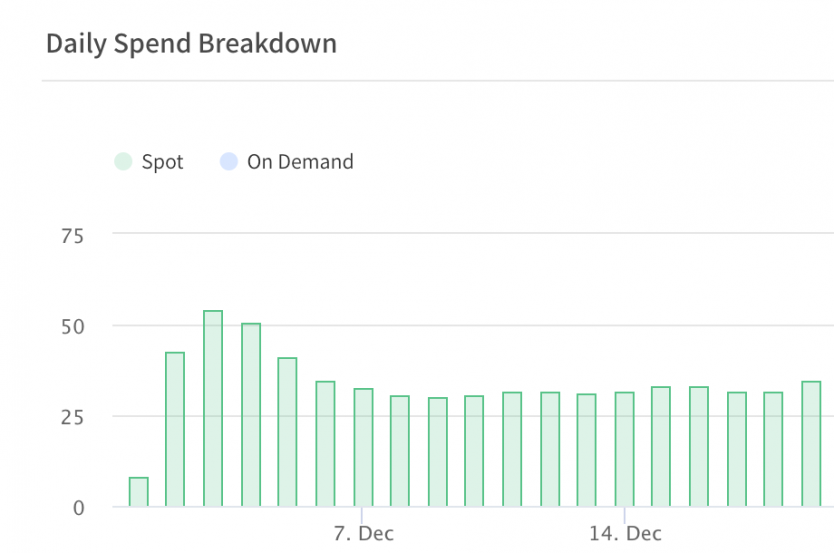
Historicals on Spot Instances
These types of nodes have the actual Druid data and are responsible, together with query nodes, of processing queries. Druid supports data replication, this allows us to put these instances on Spot instances. If we have replication factor 2, then we can lose one server. Autoscaling group will replace the server, which will boot, join the cluster and start repopulating data from deep storage.
This process might be very slow depending on the type of deep storage and the amount of data. In addition, while this process is running Druid starts rebalancing data between nodes. Rebalancing consumes computer and network resources of the cluster and could affect its performance. Speed of rebalancing is configurable, but the longer we wait, the more likely that another instance may be taken by AWS. Setting a big replication factor will affect the cost reduction coming from using Spot instances.
A solution to this problem is given by the “stateful Spot instances” provided by spot.io. The idea is simple – after replacing the instance will get the same root, data volumes and ip address. After instance is replaced, boots os and starts Druid service, it will find all segments, scan them and announce them to the coordinator. This approach allows us to replace a historical in a few mins and avoid rebalancing on cluster.
Let’s take a look at elastigroup configuration with persistence:
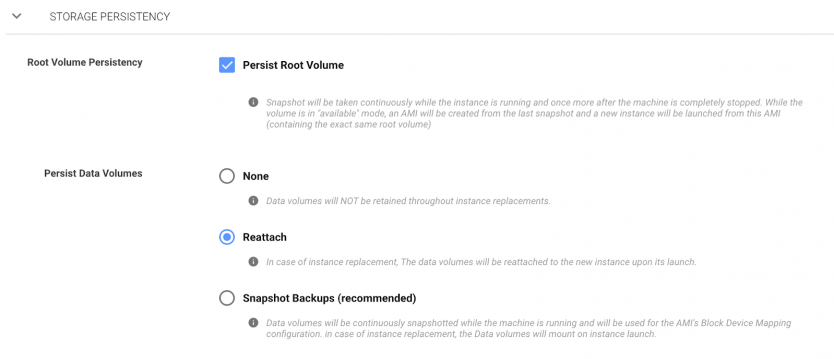
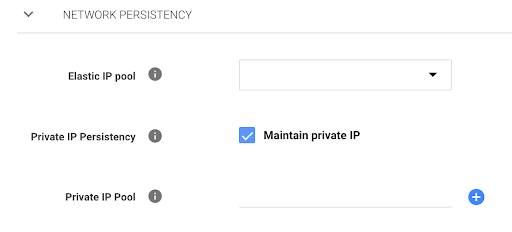
Pay attention to the different ways of reattaching volumes. The recommended one is Snapshot Backups. When you choose this option, spot.io takes a periodic snapshot of volumes and then uses them to recreate volume for replaced instances in any availability zone.
But if you use this for Druid historicals data volumes, new volumes will be created cold with significant performance degradation. To achieve regular performance you need to perform prewarming by reading all data blocks: Initializing Amazon EBS volumes, which for big volumes with terabytes of data could take a lot of time. So you should use the reattach method here.
Elastigroup also allows to preserve private ip address of Spot instance. We persist root volume with configured hostnames, to support consistency we also persist ip address. We also need this to register this node with the same hostname and ip in our monitoring systems. We didn’t check how it is likely to behave in case you just reattach data volume without root volume and ip.
Conclusions
Multicomponent design of Druid allowed us to build a fault-tolerant and scalable setup, but at the same time save costs by using AWS EC2 Spot instances. Spot.io stateful elastigroups helped us to solve the complex problem of how to run stateful services on spot instances. By leveraging the API of Druid and spot.io we were able to save even more by implementing autoscaling for Middle Manager nodes.
We hope our experience will help you to build your own cost effective druid setup by using flexibility of cloud infrastructure and scalability of Druid components.


.webp)
.jpg)


