.svg)
.webp)

At Digital Turbine, Apache Kafka is the backbone of our architecture. It ingests every event flowing through our system—ad requests, billing events, win notifications, and more—totaling around five million writes per second. It serves as the entry point for all data pipelines, where consumers read data, write it to Google Cloud Storage (GCS), or trigger downstream workflows.
Because Kafka is mission-critical, we require large, efficient, and robust clusters. However, this reliability comes with significant infrastructure costs. Disk storage drives our primary costs. To ensure consumers have time to catch up and to provide a buffer for downstream incident recovery, we retain the most recent six hours of data. Across our clusters, the total retention is over 160 TB of high-performance disk storage.
Kafka Setup
In this post, we focus on two of our critical clusters, each managing data related to a different product line.
We manage all our Kafka clusters ourselves on VMs using the open-source version of Apache Kafka 3.9.1. Combined, these two clusters operate with 10s of brokers, 100s of disks, and 100s of TB of storage. Each cluster handles approximately two million messages per second.
We utilize multiple disks per broker to bypass the bandwidth cap of individual physical disks. While a global throughput limit per VM (which scales with CPU count) still exists, this multi-disk strategy ensures we maximize the available I/O. However, this approach introduces a complexity: unless you use RAID to abstract the storage, the disk count must align with the number and size of partitions. Misalignment can lead to uneven disk usage and hot disks that throttle the entire broker.
Tiered Storage (KIP-405)
To reduce storage costs without sacrificing stability, we adopted Tiered Storage (KIP-405). This feature allows us to offload older data to cost-effective object storage (GCS), keeping only the latest hot data on expensive local disks.
Kafka Tiered Storage functions by loading a RemoteStorageManager (RSM) plugin. We decided to use the Aiven-Open RSM plugin to bridge Kafka with GCS. At the time, this was the most mature and battle-tested plugin and the obvious choice for our needs.
Producing to Kafka remains the same with Tiered Storage; incoming messages append to the active segment. When a Kafka log file rolls over (after reaching the log.segment.size or log.segment.ms configuration), the RSM splits the file into smaller chunks (configurable with rsm.config.chunk.size) and uploads them in parallel into your remote storage backend.
Once the upload is complete, the broker updates its internal RemoteLogMetadataManager (RLMM) and uploads the index and manifest files.
When a log segment reaches its local retention, it is deleted from disk, and after reaching its global retention, it is also deleted from GCS.
When consuming recent messages from Kafka, messages from the local segments are served normally. However, when reading from older offsets, the RSM fetches chunks from remote storage into a local cache (configured with rsm.config.fetch.chunk.cache.size/path/retention) and serves them from there. This allows more efficient reads for multiple consumers. You can also configure a prefetch size (rsm.config.fetch.chunk.cache.prefetch.max.size). Prefetch predicts sequential consumer reads and proactively fetches the next chunk while the current chunk is consumed, reducing latency for sequential access patterns.
It is important to ensure that the chunks cache is located on a fast, adequate disk and has sufficient size; if it’s too small or too slow, it can start deleting its own files before reading them, potentially causing various errors in various seemingly unrelated parts of the system—files not being found, timeouts exceeded, and more.
Also note that the broker keeps a cache of the remote log indexes. The broker is always located inside the first log directory that you configured, and it cannot be moved (it is hardcoded in the source code). This may be important if you are using multiple disks without RAID.
Kafka stores Tiered Storage metadata (which segments are located remotely) in an internal topic called __remote_log_metadata.
We configured the cluster to keep one hour of data on local disks and the remaining five hours on GCS. Since most consumers process data within minutes of ingestion, they rarely experience the higher latency of reading from object storage. However, when an incident occurs, the deep history remains seamlessly available.
# On the brokers and controllers
remote.log.storage.enable = true
# Per Topic
remote.storage.enable = true
local.retention.ms = 3600000 # Keep 1 hour on high-speed disk
retention.ms = 21600000 # Keep 6 hours total
cleanup.policy = delete
Switching to Local SSDs
Tiered Storage enabled our second optimization: local SSDs.
Local SSDs attach physically to the server, offering superior IOPS and throughput at a lower cost compared to network-attached persistent disks (PDs). The catch is durability—data on a local SSD is lost if the VM stops.
Previously, losing a broker meant recovering six hours of data across the network, which was risky. With Tiered Storage, we only need to recover one hour of local data—the rest remains safely persisted in GCS.
Switching to local SSD allowed us to save on storage costs and gain performance through higher disk throughput, while maintaining the cluster’s reliability and fault tolerance.
To mitigate the risk of simultaneous hardware failures, employ a Spread Placement Policy to ensure each broker resides in a distinct availability domain.
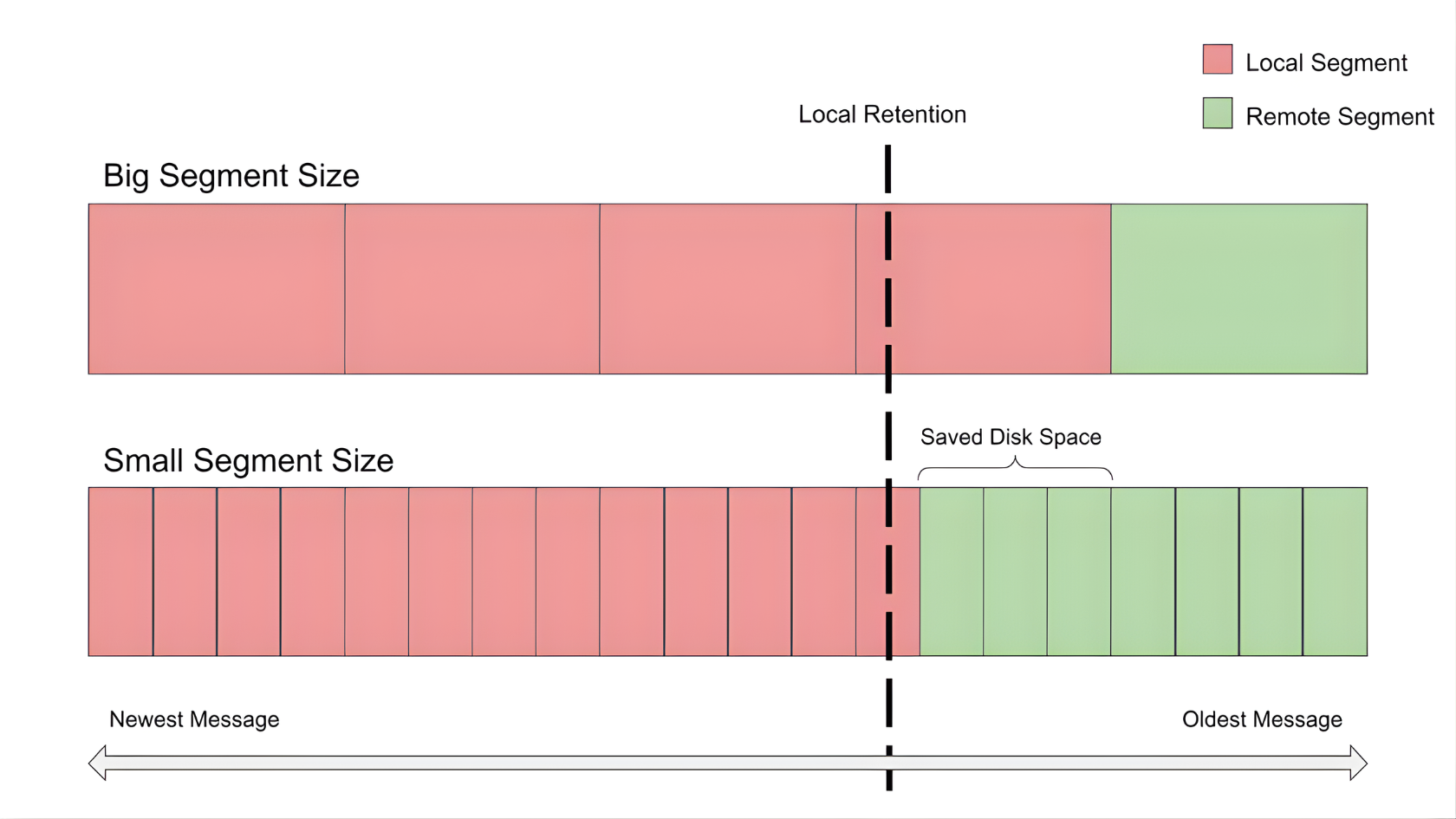
The Gotcha: Tuning Segment Sizes
When you calculate disk requirements for one hour of local retention, simple division leads to a trap.
Tiered Storage only offloads a log file (segment) once it is closed. It cannot offload the active segment currently being written to.
With our default log.segment.bytes of 1 GiB, a topic with 400 partitions and three replicas could have up to 1.2 TiB of active data sitting on disk, regardless of the retention time policy.
To reduce wasted disk space, we gradually reduced the segment size until we reached a point where the increased number of files hurt system performance. We reached a good balance by reducing the segment size for big topics from 1 GB to 200 MB, and for smaller, less busy topics to 50 MB.
This tuning significantly reduced our active disk footprint without exhausting OS file descriptor limits. These numbers are specific to our use case and depend on the traffic volume per partition replica. We recommend gradually reducing the segment size to find the optimal size for your cluster.
Results
By combining Tiered Storage with local SSDs and properly tuning segment sizes, we successfully accomplished the following:
- Maintained our six-hour retention safety net
- Increased write-throughput capabilities
- Added the ability to increase retention independently of disk size
- Reduced our Kafka infrastructure costs by over 70%
What’s Next? Use Cases for the Future
This architectural shift opens the door to new paradigms in Kafka management:
- Direct Read (KIP-1248 & KIP-1254): Currently, reading historical data requires the broker to fetch data from GCS and serve it to the consumer. Future improvements may allow consumers to read directly from object storage, bypassing the broker entirely.
- Diskless Topics (KIP-1150): If speed isn’t the primary constraint, could we store everything in object storage? This approach would eliminate the need for replication, making cluster scaling nearly instantaneous and operations significantly simpler.
Combining these ideas could fundamentally change how we operate streaming data—moving toward stateless, ultra-scalable brokers with infinite storage.


.jpg)



